This setting will allow filtering all website content by university: training programs, specialties, professions, articles. You can return to the full content of the site by canceling this setting.
This setting will allow filtering all website content by university.
- Higher School of Economics
National Research University Higher School of Economics
- IGSU
Institute of Public Service and Management
- SHFM
Higher School of Finance and Management
- RPGUP
Russian State University of Justice
- IBDA
Institute of Business and Business Administration
- VSHKU
Graduate School of Corporate Governance
- RGUTIS
Russian State University of Tourism and Service
- Moscow Poly
Moscow Polytechnic University
- RSSU
Russian State Social University
- MGRI-RGGRU them. Sergo Ordzhonikidze
Russian State Geological University named after Sergo Ordzhonikidze
- IFLA
Moscow University of Finance and Law
- Moscow Institute of Psychoanalysis
Moscow Institute of Psychoanalysis
- IGUMO and IT
Institute of Humanities Education and information technologies
- MIPT
Moscow Institute of Physics and Technology (State University)
- PRUE them. G.V. Plekhanov
Russian Economic University named after G.V. Plekhanov
- MGIMO
Moscow State Institute of International Relations (University) MFA of Russia
- Diplomatic Academy of the Russian Foreign Ministry
Diplomatic Academy of the Ministry of Foreign Affairs Russian Federation
- NRNU MEPhI
National Research Nuclear University "MEPhI"
- RANEPA
Russian Academy of National Economy and Public Administration under the President of the Russian Federation
- VAVT Ministry of Economic Development of Russia
All-Russian Academy of Foreign Trade of the Ministry of Economic Development of Russia
- Moscow State University named after M.V. Lomonosov
Moscow State University named after M.V. Lomonosov
- State IRYA them. A.S. Pushkin
State Institute of the Russian Language. A.S. Pushkin
- MGMSU them. A.I. Evdokimova, Ministry of Health of Russia
Moscow State University of Medicine and Dentistry named after A.I. Evdokimova
- RNIMU
Russian National Research Medical University named after N.I. Pirogov
- MSLU
Moscow State Linguistic University
- Financial University
Financial University under the Government of the Russian Federation
- RGAIS
Russian State Academy of Intellectual Property
- Literary Institute named after A.M. Gorky
Literary Institute named after A.M. Gorky
- PMGMU them. I.M.Sechenov
First Moscow State Medical University. THEM. Sechenov
- Russian Customs Academy
Russian Customs Academy
- Russian State University of Oil and Gas I.M. Gubkina
Russian State University of Oil and Gas named after I.M. Gubkin
- VSUYU (RPA of the Ministry of Justice of Russia)
All-Russian State University of Justice (RPA of the Ministry of Justice of Russia)
- Moscow State Technical University N.E. Bauman
Moscow State Technical University named after N.E. Bauman
- RSUH
Russian State University for the Humanities
- MISIS
National Research Technological University "MISiS"
- GAUGN
State Academic University of Humanities at the Russian Academy of Sciences
- RAM them. Gnesins
Gnessin Russian Academy of Music
- MGAVMiB them. K. I. Skryabin
Moscow State Academy of Veterinary Medicine and Biotechnology named after K.I. Scriabin
- RUDN
Peoples' Friendship University of Russia
- IPCC
Moscow State Institute of Culture
- RKhTU them. DI. Mendeleev
Russian University of Chemical Technology named after D.I. Mendeleev
- GUU
State University of Management
- AGP RF
Academy of the Prosecutor General's Office of the Russian Federation
- Moscow Conservatory P.I. Tchaikovsky
Moscow State Conservatory named after P.I. Tchaikovsky
- MGPU
Moscow City Pedagogical University
- MIET
National Research University "MIET"
- MGUTU them. K.G. Razumovsky
Moscow State University of Technology and Management. K.G. Razumovsky
Basic concepts Data processing system (information system) - a set of technical and software toolsintended for information service of people and technical objects. Classes of information systems: computing machines (VM) computing systems (VS) computing complexes (VK) VM networks are designed to solve a wide range of problems by users working in various subject areas. The main unit of the VM is the processor. The processor initializes and controls the program execution process. VK is several VMs, informationally related to each other. Moreover, each VM independently controls its own computing processes. Information exchange between the complex VMs is less intensive (in comparison with information interaction between processors in multiprocessor systems). VCs are widely used in information control systems.

The basic concepts of the aircraft are an information system tuned to solve problems in a specific field of application, i.e. it has hardware and software specialization. The VS often contains several processors, between which there is an intensive exchange of information in the process of operation, and which have a single control over the computing processes. Such systems are called multiprocessor systems. Another common type of aircraft is microprocessor-based systems. They are built using either a microprocessor (MP), or a microcontroller, or a specialized digital signal processor. Three Methods to Improve System Performance: Improvement element base, structural methods, mathematical methods. Parallel computing systems are physical computer systems as well as software systems that, in one way or another, implement parallel data processing on many computing nodes.

Flynn's classification The classification is based on the concept of a stream, which refers to a sequence of elements, instructions, or data processed by a processor. Four classes of architectures: SISD, MISD, SIMD, MIMD. SISD (single instruction stream / single data stream) is a single instruction stream and a single data stream. This class includes classical sequential machines (von Neumann type machines). In such machines, there is only one stream of commands, all commands are processed sequentially one after another, and each command initiates one operation with one stream of data. SIMD (single instruction stream / multiple data stream) - single instruction stream and multiple data stream. The command stream includes, in contrast to SISD, vector commands. This allows you to perform one arithmetic operation on many data at once - vector elements. MISD (multiple instruction stream / single data stream) - multiple instruction stream and single data stream. The definition assumes that there are many processors in the architecture that process the same data stream. There is no real computing system built on this principle yet. MIMD (multiple instruction stream / multiple data stream) - multiple instruction stream and multiple data stream. In a computer system, there are several command processing devices combined into a single complex and each working with its own stream of commands and data (multiprocessor systems).

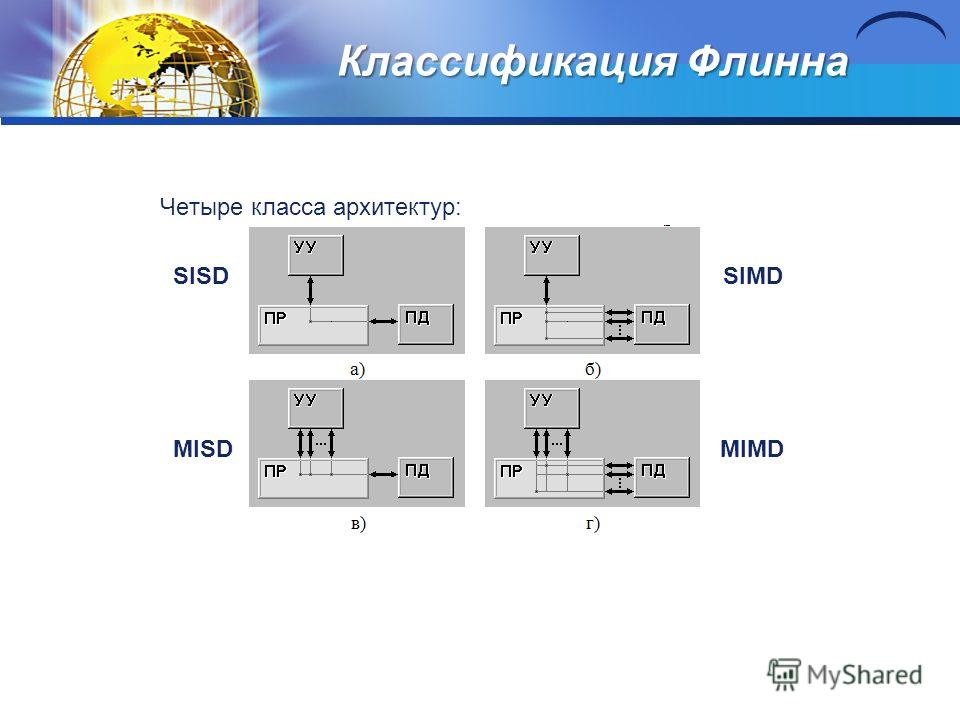
Computing systems of class SIMD Computing model: a single operation is performed on a large block of data. Two types: vector pipeline and matrix systems. Vector conveyor systems (PVP computers) Two principles in processor architecture: pipelined organization of instruction flow; introduction into the system of instructions for a set of vector operations that allow you to operate with whole data arrays. Pipelining is effective only when the conveyor loading is close to full operands corresponds to the maximum performance of the pipeline. Vector operations provide the ideal opportunity to fully load the compute pipeline. When executing a vector command, the same operation is applied to all elements of the vector. Vector commands operate on whole arrays of independent data, i.e. a command like A \u003d B + C means adding two arrays, not two numbers.

Computing systems of the SIMD class In a vector-pipeline system, there are several one or more pipeline processors that execute vector instructions by sending vector elements into the pipeline with an interval equal to the duration of one processing stage. Vector processing increases the speed and efficiency of processing due to the fact that the processing of an entire set (vector) of data is performed in one command. Vector processors should have a much more complex structure and, in fact, contain many arithmetic devices.A typical organization of a vector computing system includes: an instruction processing unit that calls and decodes instructions, a vector processor that executes vector instructions, a scalar processor that executes scalar instructions , memory for storing programs and data. The length of simultaneously processed vectors in modern vector computers is, as a rule, 128 or 256 elements.

Matrix Systems Matrix systems are best suited for solving problems characterized by the parallelism of independent objects or data. The matrix system consists of a plurality of processing elements (PE), organized in such a way that they execute vector instructions set by a common control device for all, and each PE works with a separate vector element. PEs are connected through a switching device with multi-module memory. Execution of a vector command includes reading vector elements from memory, distributing them among processors, performing a given operation, and sending the results back to memory. Thus, the system performance turns out to be equal to the sum of the performance of all processing elements.

MIMD-class computing systems MIMD architectures differ depending on whether the processor has its own local memory and accesses other blocks of memory using the switching network, or the switching network connects all processors to shared memory. Systolic Computing Systems Systolic systems are highly specialized computers and are manufactured for a specific task. In fact, the task of building a systolic calculator comes down to building a hardware pipeline that has a sufficiently long time to obtain a result (i.e. a large number of steps), but at the same time a relatively short time between sequential output of results, since a significant number of intermediate values \u200b\u200bare processed at different steps of the pipeline ... Uniform computing structures or environments (HBCs), as a rule, belong to the MIMD type and represent a regular lattice of the same type of processing elements (PE). Each PE has an algorithmically complete set of operations, as well as operations of exchange or interaction with other PE. OBC is implemented on the basis of microprocessors.

Basic principles of constructing systolic architectures 1. Systole is a network of interconnected computing cells, usually simple; 2. Each cell contains a buffer input register for data and a calculator operating with the contents of this register. The output of the calculator can be fed to the inputs of other cells; 3. Operations in systole are performed by the type of conveyor processing; 4. Calculations in systole are regulated by a common clock signal;

Basic principles of constructing systolic architectures The main characteristics of systolic VA: homogeneity of the processor field, regularity (constancy) of interprocessor connections, synchronous functioning of processor elements. At every moment of time, the same operations or the same computational modules are performed. Such modules can be: data processing and computation modules modules responsible for external communication. Each of the two types of these modules is executed in its own processing phase. Phases of systolic VA processing: K: external communication between PE; Q: calculations in PE; W: management of computation and communication (very short).

Systolic VA processing phases Communication phase. During this time interval, data are exchanged between PEs in the entire processor network. The interval should correspond in duration to the longest communication operation in the network. Calculation phase. Carries out calculations and information processing. The duration of this phase must correspond to the longest computational module. Control phase. Performs operations on the start and end of the processor field (correspond to the beginning and end of each computational operation). Stopping the processing of processes at any time before the result is obtained. The use of systolic VA: accelerators built into a PC and implementing specific computational algorithms (matrix operations, solving systems of linear algebraic equations, pattern recognition, sorting, etc.). In this case, the processor board is used as a coprocessor. The computation time is reduced by 1 - 3 orders of magnitude. systolic processors embedded in technical systems that are used for digital processing in real time. For example, a digital filtering algorithm, etc.

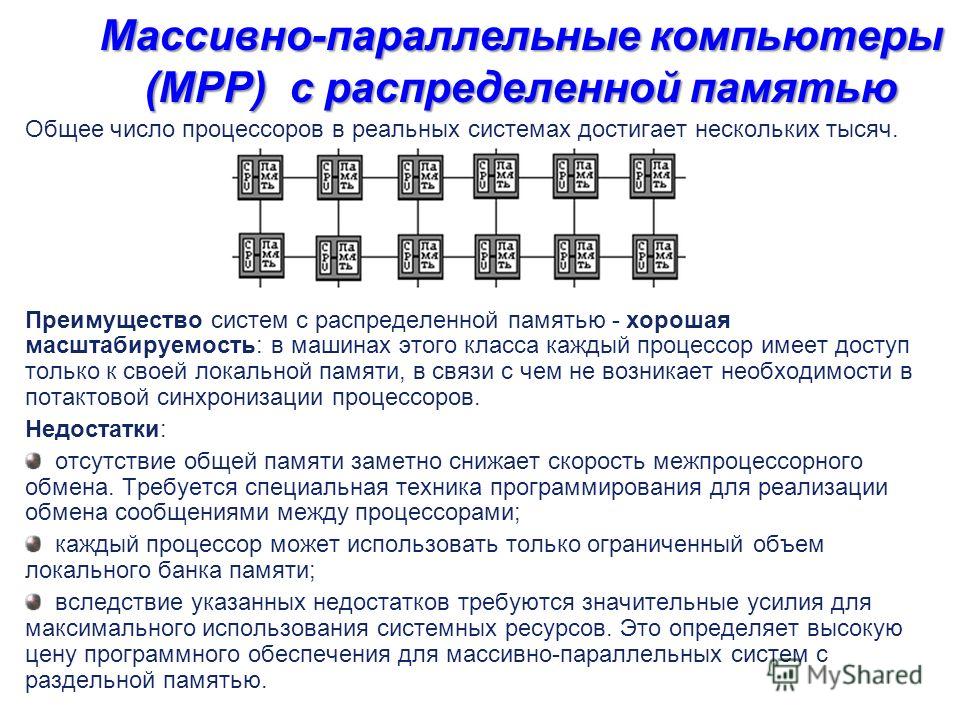
Massively parallel computers (MPP) with distributed memory The system consists of homogeneous computational nodes, including: one or more central processing units (usually RISC), local memory (direct access to memory of other nodes is not possible), communication processor or network adapter sometimes - hard drives and / or other I / O devices Special I / O and control nodes can be added to the system. The nodes are connected through a certain communication medium (high-speed network, switch, etc.) Two variants of the operating system (OS) operation on MPP-architecture machines are used: a full-fledged operating system (OS) works only on the control machine, on each individual module it functions strongly a stripped-down version of the OS, which ensures the operation of only the branch of the parallel application located in it. a full-fledged UNIX-like OS runs on each module, which is installed separately.

Massively parallel computers (MPP) with distributed memory Total number processors in real systems reaches several thousand. The advantage of systems with distributed memory is good scalability: in machines of this class, each processor has access only to its local memory, and therefore there is no need for clock-wise synchronization of processors. Disadvantages: the lack of shared memory significantly reduces the speed of interprocessor exchange. Requires special programming techniques to implement inter-processor messaging; each processor can use only a limited amount of the local memory bank; due to these disadvantages, significant efforts are required to maximize the use of system resources. This determines the high price software for massively parallel systems with separate memory.
Shared Memory Computers (SMP) SMP (symmetric multiprocessing) is a symmetric multiprocessing architecture. The main feature of systems with the SMP architecture is the presence of a common physical memory shared by all processors. The memory is used to transfer messages between the processors, while all computing devices when accessing it, they have equal rights and the same addressing for all memory cells. Therefore, the SMP architecture is called symmetric. An SMP system is built on the basis of a high-speed system bus, to the slots of which functional blocks of the following types are connected: processors (CPU), input / output (I / O) subsystem, etc. The entire system operates under a single OS. The OS automatically (during operation) distributes processes to processors, but sometimes explicit binding is also possible.

Computers with Shared Memory (SMP) The main advantages of SMP systems are: simplicity and versatility for programming: the parallel branch model is usually used, when all processors work independently of each other. However, it is possible to implement models using interprocessor communication. The use of shared memory increases the speed of such exchange; the user also has access to the entire memory volume at once. ease of use. Typically, SMP systems use an air-cooled air conditioning system to facilitate maintenance; relatively low price... Disadvantages: Shared memory systems do not scale well. This significant drawback of SMP systems does not allow them to be considered truly promising. The reason for the poor scalability is that the bus is only capable of processing one transaction at a time. concurrent access by multiple processors to the same areas of shared physical memory creates conflict resolution problems. All processors share common memory, usually via a bus or bus hierarchy. In an idealized model, any processor can access any memory location in the same amount of time. In practice, the scalability of this architecture usually results in some form of memory hierarchy. To bridge the gap in processor and main memory speed, each processor is equipped with fast buffer memory (cache) that runs at processor speed. In this regard, in multiprocessor systems based on such microprocessors, the principle of equal access to any memory point is violated and a new problem arises - the problem of cache coherence.

Shared Memory (SMP) Computers There are several possibilities to maintain cache coherency: use a bus request tracking mechanism, in which caches keep track of variables passed to any of the central processing units and, if necessary, modify their own copies of such variables; allocate a special part of memory responsible for keeping track of the validity of all used copies of variables. The main advantage of SMP systems is the relative ease of programming. Because all processors have the same fast access to the OP, the question of which processor will perform which calculations is not so fundamental, and a significant part of the computational algorithms developed for single-processor computers can be accelerated in multiprocessor systems using parallelizing and "vectorizing" compilers. SMP systems are the most common type of parallel aircraft today. In real systems, a maximum of 32 processors can be used. MPP systems allow you to create systems with the highest performance. The nodes of such systems are often SMP systems.

Computers with virtual shared (shared) memory (NUMA - systems) The architecture of NUMA (nonuniform memory access) combines the advantages of the classes of SMP systems (relative ease of program development) and MPP systems (good scalability - the ability to increase the number of processor nodes in the system). Its main feature is non-uniform memory access. The point is in the special organization of memory. Memory is physically distributed across different parts of the system, but logically it is shared so that the user sees a single address space. Each of the homogeneous modules consists of a small number of processors and a memory block. The modules are connected using a high-speed switch. A single address space is supported, access to remote memory is supported by hardware, i.e. to the memory of other modules. At the same time, access to local memory is carried out several times faster than to remote memory. Essentially, the NUMA architecture is an MPP (massively parallel) architecture, where SMP (symmetric multiprocessor architecture) nodes are taken as separate computational elements. Memory access and data exchange within one SMP node is carried out through the local memory of the node and occurs very quickly, and there is also access to the processors of another SMP node, but slower and through a more complex addressing system.

Cluster systems A cluster is two or more computers (nodes) connected by network technologies based on a bus architecture or a switch and being a single information and computing resource for the user. Servers, workstations and even ordinary ones can be selected as cluster nodes. personal computers... A node is characterized by the fact that it runs a single copy of the operating system. The health benefit of clustering becomes apparent in the event of a node failure, allowing another node in the cluster to take over the load of the failed node, and users will not notice the interruption in access. The scalability of clusters allows you to dramatically increase application performance for more users of bus architecture or switch technologies. Such supercomputer systems are the cheapest, as they are assembled on the basis of standard components, processors, switches, disks and external devices.

Cluster systems Cluster types Class I. A class of machines is built entirely from standard parts sold by many computer component suppliers (low prices, easy maintenance, hardware components available from various sources). Class II. The system has exclusive or not too widespread details. This can achieve very good performance, but at a higher cost. The way the processors are connected to each other determines its performance more than the type of processors it uses. The critical parameter is the distance between processors (it determines the amount of performance of such a system). Therefore, it is sometimes more expedient to create a system with more cheap computers than with fewer expensive ones. Clusters use oSstandard for workstations (eg freeware Linux, FreeBSD), along with special support for parallel programming and load balancing. To connect computers into a cluster, the most widely used technology is Fast Ethernet (ease of use and low cost of communication equipment).

Amdahl's Law and its Consequences An increase in the number of processors does not lead to a proportional increase in performance. Reasons 1. Lack of maximum parallelism in the algorithm and / or imbalance in the processor load. 2. Swaps, memory conflicts and timing. Suppose that in your program, the fraction of operations to be performed sequentially is f, where 0


Neurocomputational architecture To improve computer performance, it is necessary to move from von Neumann principles to parallel information processing. Nevertheless, parallel computers have not yet become widespread for several reasons. One of the options for implementing classes of computing systems architecture is a neurocomputer. A neurocomputer is a computing system with MIMD architecture, which is a collection of very simple single-type processing elements (neurons), united by multiple connections. The main advantages of neurocomputers are associated with massive processing parallelism, which leads to high performance with low requirements for the parameters of elementary nodes. Stable and reliable neural systems can be created from low-reliable elements with a large spread of parameters. Any neurocomputer in its structure is a neural network (neural network). A neural network is a network with a finite number of layers, consisting of elements of the same type - analogs of neurons with different types of communication between the layers. An elementary building element of a neural network (NN) is a neuron that carries out a weighted summation of the signals arriving at its input. The result of this summation forms an intermediate output signal, which is converted by the activation function into the output signal of the neuron.

Tasks to be solved Tasks successfully solved by the NN at this stage of their development: the formation of models and various nonlinear and mathematically difficult to describe systems, forecasting the development of these systems in time: control and regulation systems with prediction; control of robots and other complex devices; various finite state machines: queuing and switching systems, telecommunication systems; recognition of visual, auditory images; associative information search and creation of associative models; speech synthesis; the formation of a natural language; decision making and diagnostics in areas where there are no clear mathematical models: medicine, forensics, financial sphere;

Structure and properties of an artificial neuron A neuron consists of three types of elements: multipliers (synapses), an adder, and a nonlinear converter. Synapses communicate between neurons, multiply the input signal by a number that characterizes the strength of the connection (synapse weight). The adder performs the addition of signals coming through synaptic connections from other neurons and external input signals. A non-linear converter implements a non-linear function of one argument - the output of the adder. This function is called the activation function or the transfer function of the neuron.

Structure and properties of an artificial neuron A neuron implements a scalar function of a vector argument Mathematical model of a neuron: y \u003d f (s) where w i, is the synapse weight, i \u003d 1 ... n; b - offset value; s - summation result; x i - component of the input vector (input signal), i \u003d 1 ... n; y - neuron output signal; n is the number of neuron inputs; f - nonlinear transformation (activation function). In general, the input signal, weights and bias can be real values. The output (y) is determined by the type of the activation function and can be both real and whole. Synaptic connections with positive weights are called excitatory, with negative weights - inhibitory. The described computational element can be considered a simplified mathematical model of biological neurons

The structure and properties of an artificial neuron The nonlinear transformer responds to the input signal (s) with the output signal f (s), which is the output of the neuron. One of the most common is a nonlinear activation function with saturation (logistic function or sigmoid (S-shaped function): f (s) \u003d 1 / (1 + e -as) As a decreases, the sigmoid becomes flatter, in the limit at a \u003d 0 degenerating into a horizontal line at the level of 0.5, with increasing a the sigmoid approaches the form of a single jump function with a threshold of 0. From the expression for the sigmoid it is obvious that the output value of the neuron lies in the range (0, 1). One of the valuable properties of the sigmoidal function is a simple expression for its derivative. In addition, it has the property of strengthening weak signals better than large ones, and prevents saturation from large signals, since they correspond to the regions of the arguments where the sigmoid slopes gently.

Synthesis of neural networks Depending on the functions performed by neurons in the network, three types of neurons can be distinguished: input neurons, which are fed with a vector encoding an input action or an image of the external environment; they usually do not carry out computational procedures, and information is transmitted from input to output by changing their activation; output neurons, the output values \u200b\u200bof which represent the outputs of the neural network; transformations in them are carried out according to expressions (1.1) and (1.2); intermediate neurons, which form the basis of neural networks, transformations in which are also performed according to expressions (1.1) and (1.2). In most neural models, the type of neuron is associated with its location in the network. If a neuron has only output connections, then this is an input neuron, if on the contrary - an output neuron. In the process of network operation, the input vector is transformed into the output one, and some information is processed. Known neural networks can be divided according to the types of neuron structures into homogeneous (homogeneous) and heterogeneous. Homogeneous networks consist of neurons of the same type with a single activation function, while a heterogeneous network includes neurons with different activation functions.

Choice of the number of neurons and layers The number of neurons and layers is associated with: 1) the complexity of the problem; 2) with the amount of data for training; 3) with the required number of network inputs and outputs; 4) with the available resources: memory and speed of the machine on which the network is simulated; If there are too few neurons or layers in the network: 1) the network will not learn and the error during the operation of the network will remain large; 2) sharp fluctuations of the approximated function y (x) will not be transmitted at the output of the network. If there are too many neurons or layers: 1) the performance will be low, and a lot of memory will be required on von Neumann computers; 2) the network will be retrained: the output vector will transmit insignificant and insignificant details in the studied dependence y (x), for example, noise or erroneous data; 3) the dependence of the output on the input will turn out to be sharply nonlinear: the output vector will change significantly and unpredictably with a small change in the input vector x; 4) the network will be incapable of generalization: in a region where there are no or little known points of the function y (x), the output vector will be random and unpredictable, will not be adequate to the problem to be solved

Preparing input and output data Data supplied to the network input and taken from the output must be properly prepared. One of the common ways is scaling: x \u003d (x - m) c where x is the original vector, x is the scaled one. Vector m is the average value of the set of input data, c is the scale factor. Scaling is desirable to bring the data into a valid range. If this is not done, then several problems are possible: 1) the neurons of the input layer will either be in constant saturation (| m | large, the variance of the input data is small) or will be inhibited all the time (| m | small, the variance is small); 2) the weights will take very large or very small values \u200b\u200bduring training (depending on the variance), and, as a consequence, the training process will stretch and the accuracy will decrease

Network training The process of functioning of the neural network depends on the values \u200b\u200bof synaptic connections, therefore, having given a certain structure of the neural network that corresponds to a task, the network designer must find the optimal values \u200b\u200bof all variable weight coefficients (some synaptic connections may be constant). This stage is called NN training. The ability of the network to solve the problems posed to it during operation depends on how well it will be performed. At the training stage, in addition to the quality parameter of the selection of weights, the training time plays an important role. Typically, these two parameters are inversely related and must be chosen based on a tradeoff. NN training can be conducted with or without a teacher. In the first case, the network is presented with the values \u200b\u200bof both input and desired output signals, and it adjusts the weights of its synaptic connections according to some internal algorithm. In the second case, the outputs of the NN are formed independently, and the weights are changed according to an algorithm that takes into account only the input and derived signals.

Network Training Learning algorithms are divided into two large classes: deterministic and stochastic. In the first of them, the adjustment of the weights is a rigid sequence of actions, in the second, it is performed on the basis of actions that obey some random process. Consider a supervised learning algorithm. 1. Initialize the elements of the weight matrix (usually with small random values). 2. Apply one of the input vectors to the inputs, which the network must learn to distinguish, and calculate its output. 3. If the output is correct, go to step 4. Otherwise, calculate the difference between the ideal and the obtained output values: Modify the weights in accordance with a certain formula 4. Loop from step 2 until the network stops making mistakes. At the second step, at different iterations, all possible input vectors are presented in a random order. Unfortunately, there is no way to predetermine the number of iterations to be performed and, in some cases, to guarantee complete success.
